Start building with us today.
Buy this course — $99.00MongoDB 8: From Basics to Scalable Architecture
Strategic Engineering of Distributed Content Architectures: A Comprehensive MongoDB 8.0 Mastery Course
The evolution of modern digital experiences has rendered traditional, monolithic content management systems obsolete. In a global economy where a single piece of content must be served simultaneously to web browsers, mobile applications, IoT devices, and augmented reality platforms, the underlying data layer must exhibit unprecedented flexibility and performance. The architecture required to sustain 100 million requests per second demands a departure from standard database management and an entry into the realm of distributed systems orchestration. This curriculum focuses on the development of a Flexible Content Hub—a headless CMS backend designed to store unstructured document data with complex nested schemas, leveraging the cutting-edge advancements introduced in MongoDB 8.0.
Why This Course
The primary motivation for this curriculum is the historical accumulation of technical debt in high-growth enterprises. Many organizations adopt document databases for their initial developer productivity but find themselves crippled by operational instability as traffic scales toward the 100 million request threshold. This course addresses the "tiny cuts" of performance regression that occur when developers treat NoSQL as a "schema-less" dumping ground rather than a "flexible-schema" engineered system.
Engineering teams must now navigate a landscape where microseconds dictate competitive advantage. MongoDB 8.0 represents a watershed moment in database history, introducing a "Performance Army" approach to the core engine. This release has demonstrated a 36% improvement in read throughput and a 56% surge in bulk write efficiency compared to its predecessors. However, these gains are only accessible to those who understand the underlying mechanics of SIMD-vectorized execution and lock-free data structures. By grounding the curriculum in the practical intuition of storage engine internals and memory management, this course prepares architects to build systems that are not just scalable, but fundamentally predictable under stress.
Furthermore, the rise of regulatory frameworks like GDPR and HIPAA has made privacy-preserving search a core requirement. The introduction of Queryable Encryption with support for range and prefix queries allows the Content Hub to maintain data in an encrypted state throughout its entire lifecycle—at rest, in transit, and even during active query processing. This course provides the mentor-like guidance necessary to implement these complex cryptographic protocols without sacrificing the responsiveness of the CMS.
What You'll Build
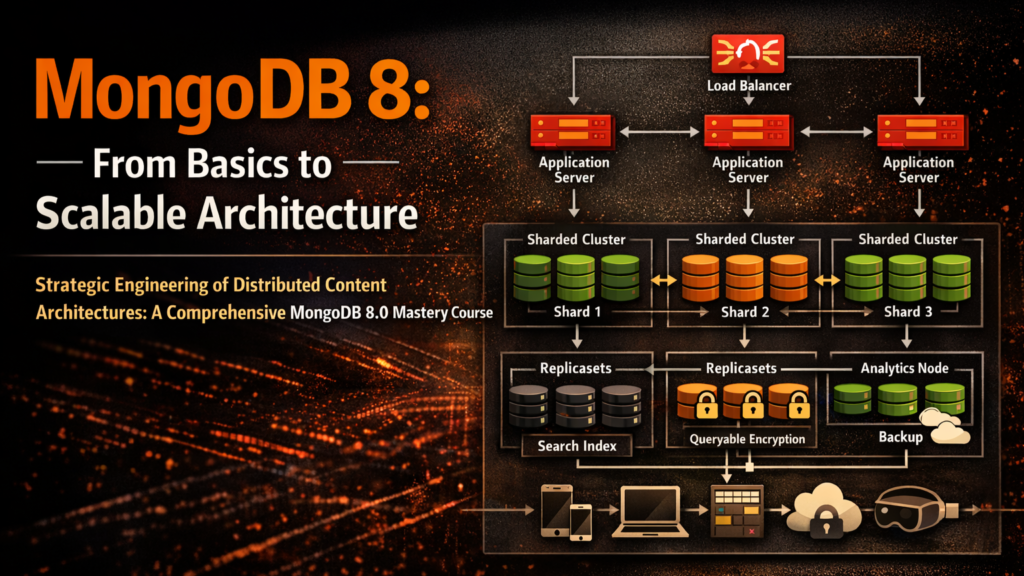
The core project of this curriculum is the Flexible Content Hub. This is not a simplified CRUD application; it is a global-scale content repository architected for mass multi-tenancy and high-dimensional data retrieval. The Hub is built to satisfy the "Create Once, Publish Everywhere" (COPE) principle, ensuring that content remains decoupled from any specific presentation layer.
The architectural core of the Hub utilizes a partitioned, multi-shard approach to ensure performance isolation across tenants. By leveraging the new moveCollection capabilities in MongoDB 8.0, the Hub can dynamically relocate unsharded collections to higher-capacity hardware as specific tenants go viral, effectively solving the "noisy neighbor" problem that plagues many SaaS platforms.
Flexible Content Hub Specification
Who Should Take This Course
The curriculum is designed to provide a unified technical language for the entire engineering organization. It recognizes that in a 100M request/sec environment, the distinction between "developer" and "SRE" becomes increasingly blurred.
Fresh computer science graduates will find an immersive environment that transforms theoretical knowledge of data structures into the practical intuition of distributed systems. They will move beyond the classroom abstraction of B-trees to understand the reality of "WiredTiger eviction pressure" and "latch contention". Senior software engineers and SREs will benefit from the deep dives into MongoDB 8.0 internals, learning to identify bottlenecks in the 12-stage execution relay and how to tune TCMalloc for per-CPU cache efficiency.
Technical Managers and Directors of Engineering will gain the strategic perspective required to manage infrastructure budgets and mitigate risk. By understanding the linear, predictable cost scaling of horizontal sharding versus the diminishing returns of vertical scaling, they can make data-driven decisions regarding cluster sizing and multi-cloud resilience.
What Makes This Course Different
Traditional database training is often a catalogue of features; this course is a manual of engineering trade-offs. We explicitly reject the "one-size-fits-all" approach to NoSQL modeling, emphasizing that schema design must be a direct reflection of the application's read-to-write ratio and working set size.
The 12-Stage Execution Relay
Unlike standard courses that stop at index creation, we trace the entire journey of a content request from the moment the network interface card (NIC) DMAs an encrypted packet into kernel memory. Learners will observe how the MongoDB ASIO reactor zero-copies the packet into a SocketFrame and how it lands on the TaskExecutor’s lock-free queue, waking worker threads in under 10 microseconds.
Storage Engine Intuition
We provide a granular exploration of the WiredTiger storage engine's transition to lock-free algorithms. Instead of relying on shared locks that serialize access to B-tree pages, we teach the implementation of hazard pointers for reads and skip lists for writes. This intuition is vital for understanding why removing lock acquisition results in a 47% increase in throughput for high-concurrency read workloads.
Quantitative Sizing vs. T-Shirt Sizing
We replace "guess-work" with the engineering formulas used by large-scale operators. Learners will use the Working Set formula to calculate RAM requirements and determine the optimal CPU-to-RAM ratio (typically 1:4) for dedicated MongoDB clusters.
Key Topics Covered
1. The Distributed Storage Core
The curriculum begins with the physics of data storage. We explore how WiredTiger utilizes MultiVersion Concurrency Control (MVCC) to provide snapshot isolation, ensuring that readers never block writers. We analyze the 60-second checkpoint interval and its impact on the Write-Ahead Log (WAL), providing the intuition to optimize commitIntervalMs for massive throughput.
2. High-Dimensional Schema Modeling
We deconstruct the myth of the "schemaless" database. Architects will learn to apply the Attribute Pattern for dynamic catalogs and the Outlier Pattern for viral content, such as a celebrity user document that exceeds the 16MB limit. We detail the mechanism of moving excess data to "overflow documents" and linking them to the parent via boolean flags.
3. The 8.0 Performance Architecture
A significant portion of the course is dedicated to the internal changes that enable 100M requests per second. This includes the implementation of the Ingress Queue for admission control and the Express Path for bypassing the query planner. We detail the role of TCMalloc’s per-CPU caches in reducing memory fragmentation by 18% in high-threaded environments.
4. Horizontal Partitioning and Sharding
Sharding is treated as a strategic decision, not a configuration toggle. We explore shard key selection based on cardinality, frequency, and monotonicity. We provide the protocol for online collection migration and converting sharded collections back to unsharded states—a new and powerful feature in MongoDB 8.0.
5. Search, Intelligence, and AI RAG Workflows
We integrate the Content Hub with modern AI paradigms. This includes leveraging Atlas Vector Search for semantic discovery and the new 8.0 quantization feature that compresses high-fidelity vectors to reduce memory footprint by 96%. We detail the "Retrieval-Augmented Generation" pipeline using Voyage AI embeddings.
Prerequisites
Engineering Foundation: Proficiency in a modern backend language (Node.js/Express, Python/FastAPI, or Go) and familiarity with asynchronous I/O models.
Database Knowledge: Baseline understanding of document-oriented storage and the B-tree structure. Conceptual awareness of replication and the CAP theorem.
Infrastructure Context: Basic familiarity with Linux memory management (huge pages) and cloud networking primitives (VPC, private endpoints).
Course Structure
The course follows a 90-day trajectory, moving from local node optimization to global cluster orchestration. Each phase concludes with a "Pressure Test" where the student's architecture is subjected to simulated viral loads.
Curriculum: 90 Hands-Hands-On Lessons
The lessons are designed as engineering tasks with specific success criteria. The tone is mentor-like, providing the "why" behind every command.
Phase 1: Local Optimization and 8.0 Primitives (Days 1–15)
Enabling FCV 8.0: Connect to a new instance and run setFeatureCompatibilityVersion: "8.0" to unlock performance-critical persistence.
Configuring Ingress Admission Control: Implement a maximum queue limit to manage incoming connections during traffic bursts.
TCMalloc Hardware Alignment: Verify that your Linux kernel is 4.18+ and enable Transparent Huge Pages to support per-CPU caches.
Verifying Per-CPU Cache Status: Use serverStatus to confirm tcmalloc.usingPerCPUCaches is true, ensuring lock-free memory allocation.
Multi-Database bulkWrite Benchmarking: Implement the 8.0 bulkWrite command to update documents in three different tenant databases in one network round-trip.
Point Lookup Sourcing via IDHACK: Execute a query by _id and use explain() to verify the execution of the IDHACK stage.
The Packet Trace Exercise: Trace a query through the TaskExecutor queue and the SCRAM auth cache to measure initial ingress latency.
Configuring Clustered Index Persistence: Create a collection where the data is physically sorted by the primary key, eliminating index-to-record hops.
Hazard Pointer Monitoring: Measure the impact of hazard pointer "publishing" versus traditional lock acquisition in a 64-thread read test.
Write Concern Majority Latency Test: Observe how 8.0 applies secondary updates while journaling to reduce majority acknowledgment time.
Implementing Global Read Timeouts: Protect the cluster from long-running aggregate queries by setting a default maximum execution time.
Configuring OCSF Log Standardization: Set up the audit log to follow the Open Cybersecurity Schema Framework for instant SIEM integration.
Establishing a Multi-Tenant Namespace: Design a naming convention that avoids collection-explosion while maintaining logical isolation.
Connection Pool Capping: Calculate and set maxPoolSize based on the available RAM to prevent "thread exhaustion".
Simulated FCV Downgrade Safety: Run transitionToDedicatedConfigServer to understand the prerequisites for rolling back 8.0 features.
Phase 2: Content Modeling and Schema Patterns (Days 16–30)
Dynamic Meta-Data with the Attribute Pattern: Create a specs array with k/v/u fields and a compound index to support arbitrary sorting.
Viral Content Management via the Outlier Pattern: Implement a "hasOverflow" flag and an "extra_comments" collection for hot documents.
Implementing Schema Versioning: Add a _schemaVersion field and write an application handler that translates legacy data shapes on-the-fly.
Content Header Denormalization: Use the Extended Reference pattern to store the author's display name and profile URL inside every article document.
Side-by-Side Localization Storage: Design a localization schema that links translations to source content using ISO 639-1 language codes.
Implementing Translation Fallbacks: Build a query pipeline that retrieves fr-FR content but defaults to en-US using the $ifNull operator.
Designing for Atomicity: Model nested "Content Blocks" (text, image, video) to ensure a single page update is atomic at the document level.
Historical Audit via Document Versioning: Set up a history collection that receives a copy of the document before every "publish" event.
Massive Array Mitigation: Identify fields that could grow indefinitely (e.g., audit_logs) and move them to a separate collection linked by ID.
Polymorphic Content Feed Construction: Create a unified activity feed that stores various document types (Post, Comment, Like) in a single collection.
Subset Optimization for High-RAM usage: Move rarely-accessed metadata into a metadata_extended collection to keep the "hot" document small.
Faceted Search via Aggregation: Build a pipeline using $facet to provide real-time counts for categories, authors, and dates.
Computed Pattern for View Counts: Implement a write-optimized counter that avoids re-reading the entire document for every view.
Schema Validation for Multi-Tenancy: Apply a $jsonSchema validator that enforces a mandatory tenantID on every insert.
Unbound Array Detection: Use the MongoDB Compass Schema Visualizer to identify documents nearing the 16MB limit.
Phase 3: Storage Engine and Performance Tuning (Days 31–45)
Tuning the WiredTiger Buffer Pool: Manually set cacheSizeGB to 60% of system RAM and monitor the "bytes currently in cache".
Analyzing SIMD-Vectorized SBE Bytecode: Profile a range-query and verify the use of in-lined numeric filters in the SBE stage.
Identifying Latch Contention Bottlenecks: Use totalTimeQueuedMicros to identify queries delayed by thread contention rather than CPU.
Checkpoint Latency Profiling: Measure the duration of WiredTiger checkpoints and identify if the storage layer (EBS/Local SSD) is a bottleneck.
Optimizing the ESR Rule for Compound Indexes: Re-index your most frequent API query to follow Equality -> Sort -> Range ordering.
Implementing Index Covering: Ensure your listing API never touches the actual documents by including all fields in a compound index.
Configuring Parallel Oplog Writers: Monitor the Decoupling of Oplog Ingestion from Oplog Application in version 8.0.
Analyzing "Scanned to Returned" Ratios: Use the Query Profiler to flag any query where the ratio exceeds 1.5, indicating poor indexing.
Configuring Adaptive Bucketizer Thresholds: Optimize time-series bucket rollover for telemetry data based on data variance.
Implementing Cooperative Yielding: Tune internalQueryExecYieldIterations to allow concurrent writes a CPU slice during long scans.
Journal Fsync Performance Audit: Adjust commitIntervalMs from 100ms to 200ms to measure throughput gains in non-critical ingestion.
Configuring TCMalloc Release Rate: Tune the rate at which TCMalloc returns unused memory to the OS to maintain a predictable RSS.
Simulating "Dirty Page" Eviction Stalls: Intentionally saturate the write throughput to document the transition to synchronous eviction.
Analyzing SBE Feedback Loops: Observe how the 8.0 query planner uses runtime feedback from previous executions to choose better plans.
Quantifying Bulk Write Compression Gains: Compare standard insertMany with 8.0 bulkWrite to measure reduction in network overhead.
Phase 4: Scaling and Horizontal Distribution (Days 46–60)
Selecting a High-Cardinality Shard Key: Design a compound shard key for content that includes tenantID and a high-entropy contentUUID.
Implementing Hashed Sharding for Uniformity: Use hashed user IDs to ensure even distribution across a 64-shard cluster.
Ranged Sharding for Geographic Locality: Configure zones to store European content on shards physically located in the EU.
Executing an Online moveCollection: Relocate an unsharded tenant collection from a busy shard to an idle one with zero downtime.
Configuring the Shard Balancer Window: Set the balancer to run only during off-peak hours (e.g., 02:00-06:00 UTC).
Detecting and Managing Jumbo Chunks: Identify chunks that cannot be split due to low-cardinality keys and implement a refined suffix.
Analyzing Sharded Data Distribution: Use sh.getShardedDataDistribution() to audit the byte-count and document-count across all shards.
Eliminating Scatter-Gather Queries: Modify the CMS API to always include the shard key in requests, targeting a single node.
Implementing Hedged Reads: Configure mongos to send read requests to multiple replicas to mask the latency of a single slow node.
Pre-Splitting Chunks for a Product Launch: Manually create 1,000 chunks before a high-profile "drop" to prevent a write-bottleneck.
Online Resharding of a Live Collection: Use the resharding tool to transition from a legacy key to a modern, high-cardinality compound key.
Configuring Global Cluster Zones: Implement data residency policies that comply with regional privacy laws.
Converting a Sharded Collection to Unsharded: Use the 8.0 unshardCollection command to simplify maintenance for a shrinking dataset.
Monitoring Migration Orphaned Documents: Use the balancer status to ensure that orphaned documents are being cleaned up correctly.
High-Throughput Chunk Migration Tuning: Adjust the new high-throughput parameter to move data 50x faster between shards.
Phase 5: Intelligence, Change Streams, and Vector Search (Days 61–75)
Implementing Real-Time Content Sync via Change Streams: Build a service that invalidates a CDN cache every time a CMS document is updated.
Configuring Change Stream Flow Control: Enable 8.0 back-pressure to pause the oplog reader if your analytics service falls >10MB behind.
Semantic Discovery with Atlas Vector Search: Implement a "Related Content" feature using a $vectorSearch stage.
Deploying Quantized Vector Embeddings: Optimize your vector index by using 8-bit quantization, reducing RAM usage by 96%.
Building a RAG Content Pipeline: Embed article text using Voyage AI and store it in a vectors array for LLM-driven query resolution.
Implementing Faceted Category Counts: Use the $facet operator to provide real-time side-bar counts for content explorers.
Aggregation Block Processing for Telemetry: Leverage 8.0 block processing to analyze CMS traffic logs 200% faster.
Sizing Dedicated Search Nodes: Deploy Atlas Search nodes with a 2:1 RAM-to-vCPU ratio to support millisecond-latency full-text search.
Optimizing Search Index Replication Lag: Measure the steady-state lag and optimize changes stream listeners for <1 second index hydration.
Implementing Hybrid Search Scores: Combine vector similarity scores with traditional TF-IDF scores using Reciprocal Rank Fusion.
Using $convert for Media Metadata: Transform Base64 media strings to binData during the content ingestion pipeline.
Configuring Adaptive Search Autocomplete: Implement "search-as-you-type" functionality using Atlas Search index mappings.
Analyzing Change Stream Tokens: Measure the 40% reduction in wire payload size using compact resume tokens in 8.0.
Implementing Change Stream Filtering: Use $match inside the stream to only alert for "critical" content updates (e.g., Breaking News).
Serverless AI Summarization: Use MongoDB triggers to automatically call an AI endpoint and populate a summary field on document creation.
Phase 6: Enterprise Rigor, Security, and load Testing (Days 76–90)
Deploying Queryable Encryption for Sensitive PII: Implement secure encryption for author phone numbers while maintaining equality search.
Implementing Encrypted Range Searches: Use the new 8.0 range algorithm to find users within a specific "age" bracket without decrypting the data.
Automatic Field-Level Encryption (CSFLE): Configure the MongoDB driver to transparently encrypt sensitive email fields before transmission.
Encryption Key Management with AWS KMS: Integrate your key vault with a hardware security module (HSM) for Master Key rotation.
Analyzing Slow Queries by "Working Time": Configure the DB Profiler to log based on workingMillis to isolate CPU-bound tasks.
Monitoring Latch Wait Stalls: Identify queries with low workingMillis but high durationMillis, indicating resource contention.
Implementing Tenant-Level RBAC: Create custom roles that restrict access to a specific tenant_id namespace.
Executing a Zero-Downtime Multi-Cloud Migration: Use Cluster-to-Cluster Sync to move content from AWS to Azure.
Configuring Multi-Region Failover: Deploy a 7-node replica set across three regions to survive a catastrophic region failure.
Executing a Point-In-Time Recovery (PITR): Simulate a data corruption event and restore the database to a state exactly 5 minutes prior.
Analyzing Query Shape Drift: Use $queryStats to detect changes in query patterns that might invalidate your current indexing strategy.
Implementing Cross-Cloud Compliance: Audit your global cluster to ensure no data from a specific region has crossed sovereign boundaries.
Optimizing Oplog Window Duration: Calculate the required oplogSizeMB to sustain a 48-hour maintenance window under 100M req/sec load.
Cloud Provider Independence Audit: Implement a multi-provider strategy to eliminate single-cloud systemic vulnerabilities.
The 100M Request/Sec Load Test Certification: Run a distributed YCSB benchmark against your Content Hub and verify sub-millisecond p99 response.
---
Technical Insights for High-Scale Content Hubs
The B-Tree vs. Skip List Trade-off in 8.0
A critical second-order insight into MongoDB 8.0's performance surge is the hybrid data structure model. While the on-disk format remains a strictly balanced B-tree to ensure predictable I/O, the in-memory representation now leverages lock-free skip lists for update operations. In a B-tree, an update requires an exclusive lock on a page, which forces other threads to serialize and wait in a queue. By using skip lists, a thread constructs the change and uses an atomic "compare-and-swap" (CAS) to put it in place. If the operation fails because another thread "won the race," the thread retries instantly rather than waiting for a lock release. This mechanism is what allows MongoDB 8.0 to handle 400% greater throughput for update-heavy workloads compared to legacy versions.
Memory Capping and the TCMalloc Revolution
For the SRE, the most significant change in 8.0 is the move from per-thread to per-CPU caching in TCMalloc. In a traditional thread-per-connection model, having 10,000 active threads meant maintaining 10,000 individual memory caches, which led to massive heap fragmentation and unsustainable resident set sizes (RSS). The new per-CPU strategy shares a single cache across all threads running on a specific core. This ensures that memory is reclaimed more aggressively, keeping the overall footprint 15-20% lower while improving translation lookaside buffer (TLB) hit rates.
The ESR Rule and Read Amplification
In high-scale CMS environments, "Read Amplification"—the phenomenon where a single API request results in multiple disk I/O operations—is the primary killer of latency. The ESR Rule (Equality, Sort, Range) is the engineering heuristic to combat this. By placing equality fields first in a compound index, you allow the engine to navigate the B-tree directly to the relevant subtree. The Sort field then ensures data is ordered in memory, avoiding an expensive "in-memory sort" that would spill to disk. Finally, the Range field captures the remaining results. Failing to follow this order often results in "scatter-gather" behavior, where the engine must scan thousands of index entries to return ten documents.
Designing for 100 Million Requests per Second
Achieving this scale is not a matter of "buying more RAM"; it is a matter of distributed coordination. The following table provides the operational targets for a production-grade 8.0 cluster.
Conclusion: The Architecture of Resilience
Engineering a Flexible Content Hub that sustains 100 million requests per second requires a fundamental shift in perspective. It is an acknowledgment that the database is not an isolated component, but a high-speed relay system between the network and persistent storage. The advancements in MongoDB 8.0—from lock-free B-tree traversal to SIMD-vectorized execution—provide the tools, but the architect must provide the rigor.
By mastering the transition from lock-acquisition to hazard-pointer publication, technical teams can remove the serialization bottlenecks that have historically capped single-node throughput. Furthermore, the evolution of Queryable Encryption to support complex range queries ensures that global scale does not come at the cost of data sovereignty. Ultimately, this course empowers technical leaders to move away from the reactive "emergency vertical scaling" model toward a proactive, linearly predictable horizontal architecture. In the landscape of 2026, where cloud independence is a strategic imperative, a battle-tested MongoDB 8.0 Hub stands as the resilient backbone of the enterprise digital ecosystem.