Start building with us today.
Buy this course — $174.97MLOps Engineering – From Training to Automated Production
The Industrialization of Machine Learning: A Comprehensive Guide to Automated Model Lifecycles at Scale
The contemporary landscape of artificial intelligence is characterized by a profound paradox: while the mathematical sophistication of neural architectures has reached unprecedented heights, the operational infrastructure required to sustain these models in production remains remarkably fragile. Traditional software engineering, predicated on deterministic logic and static codebases, is often ill-equipped to handle the probabilistic and data-dependent nature of machine learning. Statistics from industry leaders suggest that fewer than twenty percent of developed machine learning models ever reach a production environment, representing a significant failure to materialize the intended business value. This gap is not merely a technical oversight but a systemic failure of the "handover" process between research-oriented data scientists and operations-focused engineers. MLOps, or Machine Learning Operations, has emerged as the critical discipline required to bridge this divide, applying the rigor of DevOps to the volatility of data-intensive workflows.
As organizations attempt to scale from a single predictive model to thousands, the "artisanal" approach of manual retraining and ad-hoc deployment inevitably collapses. The complexity of managing these models is further amplified when request volumes reach the threshold of 100 million requests per second (RPS), necessitating an architecture that balances ultra-low latency with massive compute density. This report details a comprehensive pedagogical framework designed to transform participants into MLOps architects capable of designing, building, and maintaining self-healing, high-scale machine learning systems using the synergistic combination of Kubeflow and MLflow.
Why This Course?
The necessity of a formalized MLOps curriculum stems from the realization that machine learning in production is a "systems problem" rather than just a "modeling problem". The industry is currently facing a talent shortage of engineers who understand the "hidden ninety percent" of machine learning—the infrastructure, data lineage, and monitoring required outside the core training script. Most existing educational resources focus on model accuracy or basic deployment, failing to address the silent degradation of models in the wild. This course is positioned to solve the four major "bottlenecks" that prevent machine learning maturity: fragmented data traceability, feature inconsistency between training and serving, disconnected environments, and the lack of automated feedback loops.
The curriculum recognizes that a model's lifecycle does not end at deployment. In fact, deployment is merely the beginning of a continuous cycle of monitoring, drift detection, and automated retraining. By focusing on ultra-high-scale system design, the course prepares practitioners for the most demanding environments where P99 latency is the primary metric of success. The integration of Kubeflow for container-native orchestration and MLflow for experiment tracking provides a balanced toolkit that is widely adopted by leading technology firms.
What You'll Build
Participants will construct an end-to-end, "closed-loop" MLOps system that serves as a blueprint for modern industrial AI applications. This capstone project, the "Automated Model Assembly Line," is designed to handle a real-world use case—such as fraud detection or recommendation systems—at a scale of 100 million requests per second. The system is not a static artifact but a dynamic ecosystem of interconnected pipelines.
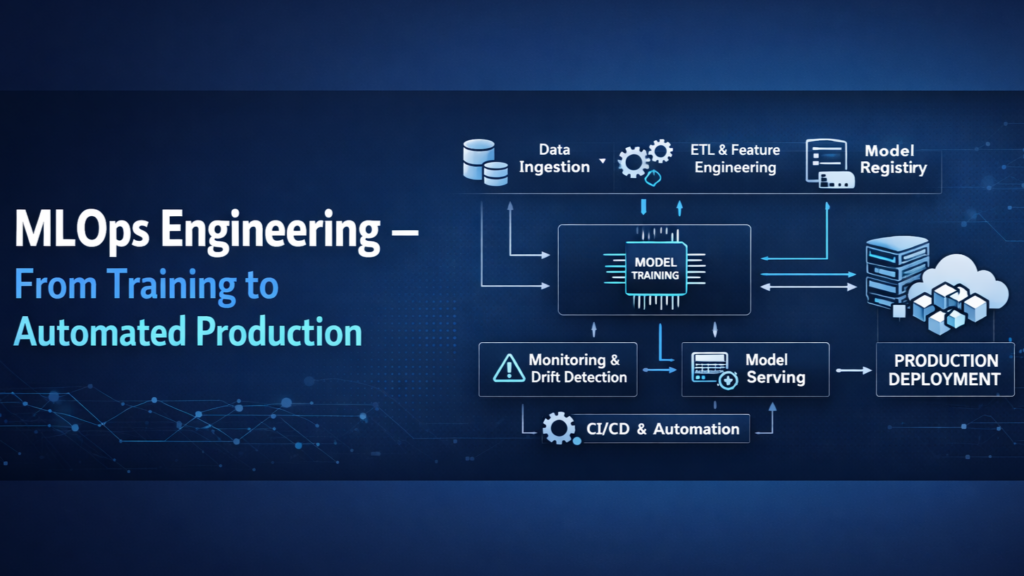
The Automated Assembly Line Architecture
The system architecture follows a modular design, where each layer is responsible for a specific phase of the model lifecycle. The "Ingestion Layer" uses automated pipelines to validate and preprocess incoming data, ensuring that features are consistent across training and serving environments. The "Orchestration Layer," powered by Kubeflow, manages the Directed Acyclic Graph (DAG) of tasks, from hyperparameter tuning with Katib to model evaluation.
A critical component of this project is the "Feedback and Retraining Loop." A monitoring service continuously tracks the statistical properties of production data, calculating metrics such as the Population Stability Index (PSI) and Kolmogorov-Smirnov (KS) test statistics. When significant data drift is detected—indicating that the incoming data has diverged from the training distribution—the system automatically triggers a retraining pipeline. This pipeline pulls the latest "ground truth" labels, executes a new training run, and logs the results to the MLflow Model Registry. If the new model version meets predefined performance "gates," it is automatically promoted to production via a canary rollout, replacing the degraded model.
Who Should Take This Course?
This curriculum is designed for a diverse cohort of professionals who share a common goal: the successful operationalization of machine learning. The depth of the course ensures that each role gains both a high-level strategic perspective and granular technical skills.
For Machine Learning Engineers, the course provides the necessary transition from "model builders" to "system architects." They will learn how to wrap their training logic in robust, containerized components that can survive the rigors of a production environment. DevOps and Site Reliability Engineers (SREs) will find this course essential for understanding the unique resource demands of ML, such as GPU scheduling, large model artifact storage, and the stateful nature of data versioning.
Data Scientists will benefit from learning the constraints of production, which will inform their experimentation process and ensure that the models they design are actually deployable. Finally, Engineering Managers and Product Managers will gain the technical literacy required to make high-stakes trade-offs between model accuracy and system latency, while ensuring that their organizations are compliant with emerging AI governance regulations.
What Makes This Course Different?
The primary differentiator of this course is its focus on the "Level 2" maturity of MLOps, where automation is not just a luxury but a fundamental requirement for survival. Unlike traditional courses that focus on a single cloud vendor's platform, this curriculum emphasizes an open-source, vendor-agnostic stack centered on Kubeflow and MLflow.
Focus on Ultra-High Scale (100M RPS)
The course addresses the extreme architectural challenges of serving models to 100 million users simultaneously. This involves a deep dive into "no-wait" dynamic batching, which optimizes GPU utilization by processing requests as they arrive rather than waiting for fixed batch sizes. Participants will learn how to design systems that achieve "eleven nines" of durability and sub-50ms P99 latency, mirroring the infrastructure of global services.
The "Hidden Ninety Percent" Philosophy
Borrowing from the "Inverted 80/20 Rule," the course dedicates significant time to the infrastructure and operations that consume the majority of a production system's complexity. This includes the implementation of feature stores to ensure feature parity between training and serving, the management of "cold starts" during auto-scaling, and the design of trust-building UI/UX patterns that provide users with model explainability and agency.
Key Topics Covered
The curriculum is structured around five core pillars of modern MLOps, each representing a critical stage in the automated model lifecycle.
Experiment Tracking and Reproducibility: Mastering the use of MLflow to create a "digital paper trail" for every model. This ensures that any production model can be perfectly reproduced by tracing its lineage back to the exact code commit, data snapshot, and hyperparameter configuration.
Containerized Pipeline Orchestration: Using Kubeflow to design modular, reusable components. This allows for the creation of "parameterized" pipelines that can be easily adapted for different datasets or use cases without rewriting the underlying logic.
Real-Time Monitoring and Self-Healing: Implementing advanced drift detection mechanisms. Students will learn how to use statistical tests to identify covariate shift and concept drift, and how to configure event-driven triggers that initiate retraining before model performance impacts business KPIs.
High-Scale Inference Engineering: Designing serving layers that balance throughput and latency. This includes exploring hardware-specific optimizations like TensorRT for GPUs, the use of Multi-Instance GPU (MIG) for resource isolation, and the implementation of circuit breaker patterns to ensure system resilience.
Model Governance and Safety: Addressing the ethical and legal dimensions of AI. The course covers model explainability (SHAP, LIME), bias detection, and the implementation of automated "quality gates" that prevent unsafe or inaccurate models from reaching production.
Prerequisites
To ensure that the cohort moves at an accelerated pace, participants are expected to meet a rigorous technical baseline.
Programming Mastery: Strong proficiency in Python, including the ability to write modular, testable code and a deep familiarity with the PyData stack (Pandas, NumPy, Scikit-Learn).
Infrastructure Foundations: A working knowledge of Linux environments and the fundamentals of containerization (Docker) and orchestration (Kubernetes basics).
Machine Learning Fundamentals: Understanding the standard ML lifecycle, including data preprocessing, feature engineering, and the evaluation of classification and regression models.
Cloud Proficiency: Experience with at least one major cloud provider (AWS, Azure, GCP) and an understanding of basic CI/CD principles.
Course Structure: The 90-Day Transformation
The course is structured as a twelve-week intensive journey, divided into three distinct phases that track the evolution of an MLOps platform from a "repeatable" state to a "reliable" and "scaling" state.
Curriculum: 90 Lessons for the MLOps Elite
The curriculum consists of ninety modular lessons, designed to be consumed at a rate of seven to eight lessons per week, with dedicated time for the hands-on capstone project.
Week 1: Strategic Foundations and the MLOps Mindset
Lesson 1: The Great Handover Crisis: Why 80% of Models Fail to Reach Production.
Lesson 2: MLOps vs. DevOps: Mapping the Unique Challenges of Non-Deterministic Systems.
Lesson 3: The MLOps Maturity Model: Evaluating Your Organization's Current State.
Lesson 4: Introduction to the "Assembly Line": Treating Models as Industrial Products.
Lesson 5: Business Alignment: Defining KPIs for MLOps Success beyond Model Accuracy.
Lesson 6: The Strategic "Iron Triangle": Balancing Cost, Latency, and Accuracy in Large-Scale AI.
Lesson 7: Case Study: Scaling Demand Forecast Models for Global Retailers.
Week 2: Environment Orchestration and Kubernetes for ML
Lesson 8: Designing the Developer Workspace: From Local Notebooks to Remote Clusters.
Lesson 9: Kubernetes Core for ML: Pods, Deployments, and Resource Constraints.
Lesson 10: Persistent Storage in Kubernetes: Managing Model Weights and Datasets with MinIO.
Lesson 11: Networking for ML: Istio, Service Mesh, and Ingress for Model APIs.
Lesson 12: Building Optimized Container Images: Multi-Stage Builds and Arm64 Runners.
Lesson 13: Resource Isolation: Using Multi-Instance GPU (MIG) for Multi-Tenant Clusters.
Lesson 14: Security in the ML Stack: Identity Management and Network Policies.
Week 3: Data Lineage, Versioning, and Feature Stores
Lesson 15: The Trinity of Versioning: Syncing Code, Data, and Model States.
Lesson 16: Solving Train-Serve Skew: Ensuring Consistency in Feature Logic.
Lesson 17: Data Version Control (DVC): Implementing Immutable Data Snapshots.
Lesson 18: The Feature Store Paradigm: Offline vs. Online Feature Access.
Lesson 19: Implementing Feast: Centralizing Feature Definitions across Teams.
Lesson 20: Temporal Aggregations: Calculating Real-Time "Always-Fresh" Features.
Lesson 21: Data Validation at Scale: Using Great Expectations for Automated Quality Checks.
Week 4: Experiment Tracking with MLflow
Lesson 22: MLflow Tracking Architecture: Server, Backend Store, and Artifact Store.
Lesson 23: Logging with Precision: Parameters, Metrics, and Model Signatures.
Lesson 24: Comparing Experiments: Advanced Visualization and Search in the MLflow UI.
Lesson 25: Programmatic Model Comparison: Using the MLflow Client API.
Lesson 26: Reproducible Projects: Defining Conda and Docker Environments in MLflow.
Lesson 27: Tracking Large Artifacts: S3 and GCS Backends for MLflow.
Lesson 28: Autologging and Deep Integration: Scikit-Learn, PyTorch, and XGBoost.
Week 5: Model Governance and the Registry Workflow
Lesson 29: The Model Registry: Bridging Experimentation and Production.
Lesson 30: Versioning Strategies: Incremental vs. Semantic Versioning for Models.
Lesson 31: Stage Transitions: From "None" to "Staging" and "Production".
Lesson 32: Using Aliases (@champion) for Dynamic Model Routing.
Lesson 33: Implementing Automated Promotion: Scripting the Approval Workflow.
Lesson 34: Model Lineage: Tracing a Production Model to its Parent Training Run.
Lesson 35: Governance in Regulated Industries: Audit Trails and Access Controls.
Week 6: Kubeflow Pipelines (KFP) Mastery
Lesson 36: KFP Architecture: Containers, Argo Workflows, and ML Metadata.
Lesson 37: Designing Modular Components: Using the KFP Python SDK.
Lesson 38: Data Passing and Artifacts: Typed Inputs and Outputs in KFP.
Lesson 39: Conditional Execution and Branching: Building Intelligent Pipelines.
Lesson 40: Parallelism and Loops: Scaling Training across Multiple Worker Nodes.
Lesson 41: Pipeline Caching: Optimizing Developer Velocity through Component Reuse.
Lesson 42: Complex DAG Design: Managing Interdependencies in High-Frequency Workflows.
Week 7: Integrating MLflow and Kubeflow for End-to-End Automation
Lesson 43: Architecting the Integrated Stack: Orchestrator vs. Lifecycle Manager.
Lesson 44: Implementing the MLflow Component inside Kubeflow Pipelines.
Lesson 45: Environment Injection: Managing MLFLOWTRACKINGURI in KFP Pods.
Lesson 46: Automated Hyperparameter Tuning: Integrating Katib with MLflow.
Lesson 47: Logging Pipeline Metadata as MLflow Tags for Full System Visibility.
Lesson 48: Tracking Dataset Versions across the KFP-MLflow Boundary.
Lesson 49: Troubleshooting Shared Identity and Permissions between KFP and MLflow.
Week 8: Continuous Monitoring and Automated Retraining Triggers
Lesson 50: The "Model Performance Gap": Identifying When Models Fail Silently.
Lesson 51: Covariate Shift: Measuring Statistical Divergence in Input Features.
Lesson 52: Concept Drift: Detecting Changes in Feature-Target Relationships.
Lesson 53: The Population Stability Index (PSI) Deep Dive: Implementation and Interpretation.
Lesson 54: Setting Thresholds: Differentiating Noise from Sustained Drift.
Lesson 55: Implementing the Drift Detection Service with Evidently AI.
Lesson 56: Automated Retraining: Triggering KFP from External Drift Alerts.
Week 9: High-Scale Inference Engineering (Part I)
Lesson 57: Inference vs. Training: Why Inference is the "Hidden 90%".
Lesson 58: Scaling to 100M RPS: Architecting for Infinite Horizontal Scale.
Lesson 59: Dynamic Batching: Optimizing Throughput without Sacrificing Latency.
Lesson 60: No-Wait Batching: Case Study of Snowflake's Optimized Inference Engine.
Lesson 61: Latency Budgeting: Allocating Milliseconds across the Gateway and Feature Store.
Lesson 62: Asynchronous Inference: Decoupling Prediction from Consumption.
Lesson 63: Batch Scoring Pipelines: High-Throughput Processing for Millions of Records.
Week 10: High-Scale Inference Engineering (Part II)
Lesson 64: Model Compilers: Using TensorRT and ONNX Runtime for Hardware Acceleration.
Lesson 65: Precision Engineering: Quantization (FP16, INT8) and its Impact on Scale.
Lesson 66: Paged Attention and KV Caching: Scaling LLM Inference to Millions of Tokens.
Lesson 67: Managing "Cold Starts": Predictive Scaling and Warm Instance Pools.
Lesson 68: Memory Leak Prevention in Long-Running Python Inference Services.
Lesson 69: Benchmarking: Maintaining Flat P99 Latency Curves under Heavy Load.
Lesson 70: Cost Optimization: Maximizing RPS per GPU Dollar.
Week 11: Safe Deployment and Model Rollout Patterns
Lesson 71: The Progression of Safety: From Evaluation to Shadow Mode to Production.
Lesson 72: Implementing Shadow Mode: Capturing Predictions without impacting Users.
Lesson 73: Canary Rollouts: Shifting 1-5% of Traffic to New Model Candidates.
Lesson 74: Traffic Shifting with Service Mesh (Istio) and KServe.
Lesson 75: Automated Rollback: Triggering Version Reversion based on Real-Time Error Rates.
Lesson 76: Multi-Model Gateways: Routing Requests across Diverse Serving Containers.
Lesson 77: Multi-Region Serving: Reducing Latency for a Global User Base.
Week 12: Advanced Operations, Explainability, and Governance
Lesson 78: Explainable AI (XAI) in Production: Local vs. Global Explanations.
Lesson 79: Implementing SHAP and LIME for Real-Time Prediction Transparency.
Lesson 80: Bias and Fairness Monitoring: Identifying Disparate Impact in Real-Time.
Lesson 81: Human-in-the-Loop (HiL): Design Patterns for Manual Override and Active Learning.
Lesson 82: Observability beyond Metrics: Tracing, Logging, and Introspection.
Lesson 83: Security: Defending against Model Inversion and Adversarial Attacks.
Lesson 84: Regulatory Compliance: Audit READINESS and the ML Model Bill of Materials.
Week 13: Capstone Implementation and Professional Synthesis
Lesson 85: Capstone Part I: Designing the Automated Retraining Trigger Logic.
Lesson 86: Capstone Part II: Building the Kubeflow-MLflow Bridge for the "Assembly Line".
Lesson 87: Capstone Part III: Stress-Testing the Serving Layer at 100M RPS.
Lesson 88: Capstone Part IV: Implementing Automated Model Promotion Gates.
Lesson 89: Final Project Review, Documentation, and Reproducibility Audits.
Lesson 90: Graduation: Continuous Improvement and the Future of AI Systems.
Learning Objectives
The curriculum is designed to move participants through a Bloom's Taxonomy of MLOps, from "Understanding" to "Creating" ultra-high-scale systems.
Mastery of the Lifecycle
Participants will demonstrate the ability to orchestrate the entire end-to-end process, from data collection and model development to deployment, monitoring, and continuous retraining. They will move beyond "manual" training to designing systems where model updates occur without human intervention.
Statistical and Operational Vigilance
Participants will master the statistical tests required to detect data drift, such as the Population Stability Index (PSI), and learn how to translate these values into actionable triggers for retraining. They will also develop the skills to monitor "golden signals" of infrastructure—latency, throughput, errors, and saturation—specifically for machine learning workloads.
Architectural Competence at Scale
Engineers will be able to design inference architectures that handle 100M RPS while maintaining sub-50ms P99 latency. This includes mastering dynamic batching, hardware acceleration, and memory-efficient serving patterns.
Governance and Ethical Responsibility
Graduates will be equipped to implement model governance frameworks that ensure auditability, explainability, and compliance with global regulations. They will learn to view every model not as a "black box" but as a transparent system with clear lineage and accountability.
The 100M RPS Challenge: Architecting for Global Scale
Achieving a throughput of 100 million requests per second requires a fundamental rethinking of the standard "Model-as-a-Service" approach. At this scale, the traditional bottlenecks of Python's Global Interpreter Lock (GIL) and network overhead become existential threats to the system's viability.
No-Wait Dynamic Batching
The most critical optimization for high-scale serving is the implementation of "no-wait" dynamic batching. Traditional batching systems introduce a "wait timer" (e.g., 5ms) to accumulate requests into a batch of a specific size (e.g., 64). However, at 100M RPS, requests arrive at a rate that makes these timers obsolete. A "no-wait" engine simply batches all requests currently waiting in the queue the moment the GPU completes its previous task. This approach adaptively shifts between low-latency single processing during light loads and high-throughput batch processing during heavy spikes, without requiring manual tuning.
Request Pipelining and High-Performance Runtimes
To further optimize throughput, the architecture must leverage "request pipelining," which pre-queues the next inference task while the current one is being processed by the hardware. This eliminates the idle time between requests. Additionally, moving from framework-native serving (e.g., PyTorch) to compiled runtimes like TensorRT can result in a 30-fold increase in inference speed, allowing fewer nodes to handle significantly higher traffic.
Operational Wisdom: The "Hidden 90%" of MLOps
Production MLOps is distinguished from experimentation by its focus on resilience and predictability. Senior mentors emphasize that "behavior is probabilistic" and "systems degrade silently," making traditional monitoring insufficient.
Drift Detection Math and Strategy
The Population Stability Index (PSI) is the industry standard for measuring covariate shift. It is calculated by binning the continuous features and comparing the proportion of samples in each bin between the reference (training) and current (production) data.
However, mentors warn against "blindly" retraining based on statistical tests alone. For example, in the retail market, a sudden shift in behavior during "Black Friday" might be flagged as drift, but retraining on this seasonal noise could "break" the model for normal shopping days. The curriculum teaches students to combine statistical alerts with hard business metrics and human-in-the-loop approval stages.
Trust and Explainability in User Experience
At high scale, user trust is a "multifaceted construct" built on Ability, Benevolence, Integrity, and Predictability. The course emphasizes UX patterns that build trust by signaling AI confidence, making failure states visible, and preserving user agency. For high-impact decisions, such as fraud detection, providing a "Because" statement—supported by SHAP feature importance—allows users to understand and trust the automated outcomes.
Conclusion: Engineering the Future of AI
The industrialization of machine learning is not a project with a fixed endpoint, but a fundamental shift in how organizations build and operate technology. By treating machine learning models as parts of an automated, self-healing assembly line, organizations can scale from one model to thousands without losing control, quality, or speed.
This course prepares a new generation of MLOps architects to navigate this complexity. By mastering the synergy between Kubeflow's orchestration and MLflow's governance, and by architecting for the extreme demands of 100 million requests per second, practitioners will ensure that AI delivers on its promise of transformation. The future of AI is not just about the accuracy of the prediction; it is about the reliability, scale, and trust of the system that produces it.