Start building with us today.
Buy this course — $175.00Advanced Java for Banking and Ledger Systems
The Engineering of Global Ledger Systems: High-Throughput Financial Core Architectures in Java
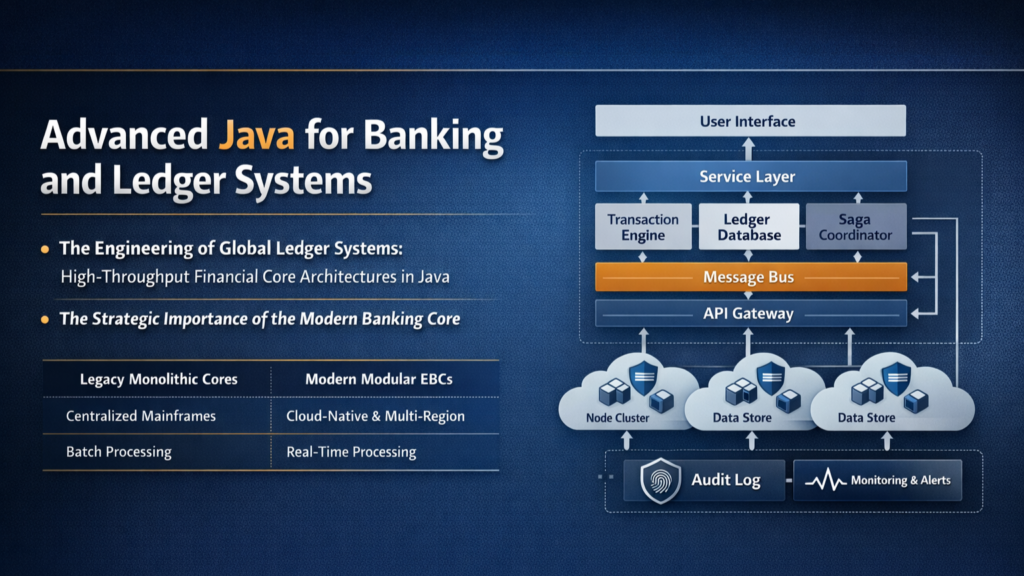
The architectural paradigm of modern enterprise banking cores has shifted from the rigid, monolithic structures of the mainframe era toward ultra-scalable, modular engines capable of processing millions of transactions per second with sub-millisecond latency. This evolution is not merely a change in technology stack but a fundamental reimagining of how financial truth is recorded and reconciled in a globally distributed environment. At the center of this transformation lies the Java ecosystem, which provides the robust concurrency models, memory management, and enterprise-grade libraries required to build systems that are both highly performant and financially unassailable.
The Strategic Importance of the Modern Banking Core
The core banking system serves as the operational backbone of any financial institution, acting as the definitive system of record for customer assets, identities, and transaction histories. In the legacy era, these systems were designed for consistency above all else, often relying on vertical scaling and batch processing to maintain the general ledger. However, the rise of digital-native fintech platforms and the demand for real-time payments have rendered these legacy architectures obsolete. Modern cores must now support horizontal scalability, high availability across multiple regions, and event-driven responsiveness while maintaining the absolute integrity of the double-entry bookkeeping principle.
The transition to a modern architecture involves a layered approach that separates concerns into distinct horizontal tiers: presentation, business logic, data access, and integration. This separation allows for the independent scaling of services and facilitates the implementation of the Strangler Pattern, where legacy components are gradually replaced by microservices without disrupting ongoing operations. For the software architect, the goal is to design a core that is not merely a passive repository of data but an active strategic enabler of innovation, regulatory compliance, and operational excellence.
Comparative Evolution of Core Banking Systems
Numerical Integrity: The Mathematics of Financial Correctness
In the engineering of a banking core, the representation of monetary values is perhaps the most critical low-level decision. A common pitfall for novice engineers is the use of floating-point primitives such as float or double. These types utilize binary floating-point arithmetic (IEEE 754), which cannot accurately represent decimal fractions like 0.1. Over millions of transactions, these minor precision errors accumulate, leading to material discrepancies in account balances—a catastrophic failure in a financial system.
The BigDecimal Standard and Rounding Modes
Java’s java.math.BigDecimal provides an arbitrary-precision signed decimal number consisting of an unscaled value and a scale. The relationship is defined as:
![][image1]
While BigDecimal ensures precision, it is an immutable object, meaning every operation results in a new object allocation, which can impact performance in high-frequency scenarios. Furthermore, developers must explicitly define rounding behaviors. The industry standard for banking is HALF_EVEN, also known as "banker's rounding," which minimizes cumulative rounding bias by rounding toward the nearest even neighbor when equidistant.
High-Performance Concurrency: Beyond Traditional Locks
When a banking core must handle hundreds of thousands of concurrent account updates per second, traditional Java synchronization becomes a bottleneck. The use of the synchronized keyword or standard ReentrantLock forces threads into a blocked state, triggering expensive context switches between user space and the kernel. At extreme scale, the time spent managing locks exceeds the time spent on actual business logic.
Mechanical Sympathy and the LMAX Disruptor
To achieve ultra-high throughput, engineers employ "mechanical sympathy"—designing software that aligns with the physical realities of modern CPU architecture. CPUs operate on cache lines, typically 64 bytes in size. If a producer thread and a consumer thread update variables that happen to be on the same cache line, the CPU must invalidate the cache for the other core, leading to "false sharing" and degraded performance.
The LMAX Disruptor addresses this by utilizing a pre-allocated Ring Buffer and memory padding. By inserting "padding" fields (unused long variables) around critical sequence numbers, the system ensures that different threads work on distinct cache lines. Furthermore, the Disruptor is lock-free, utilizing Compare-And-Swap (CAS) operations to coordinate access, allowing for millions of transactions per second on a single thread.
Comparison of Locking Strategies in High-Scale Java
Distributed Consistency and the Saga Pattern
In a distributed microservices ecosystem, maintaining a consistent state across different databases (e.g., a transfer from Account A in Region 1 to Account B in Region 2) requires advanced coordination patterns. Traditional Two-Phase Commit (2PC) is often avoided in modern fintech due to its lack of scalability and the "blocking" nature of the protocol during network partitions.
Orchestration vs. Choreography in Sagas
The Saga pattern breaks a distributed transaction into a series of local transactions. If one step fails, the system executes compensating transactions to roll back previous successful steps, ensuring eventual consistency. Architects must choose between Orchestration, where a central "Saga Coordinator" directs the participants, and Choreography, where services communicate via events.
For an enterprise banking core, Orchestration is often preferred for complex workflows like loan origination because it provides a centralized view of the transaction state and simplifies debugging. However, Choreography offers higher decoupling for simple P2P transfers, allowing the system to scale without a central bottleneck.
Kafka and Exactly-Once Semantics (EOS)
To ensure that a transaction is not processed twice during a network retry (idempotency), banking cores leverage Kafka’s exactly-once semantics. By using transactional producers and consumer isolation levels set to read_committed, the core guarantees that all messages in a transaction are either visible to consumers or none are. This mechanism is vital for preventing double-crediting of accounts—a common point of failure in distributed financial systems.
Forensic Auditing and The Immutable Audit Trail
Regulatory frameworks like SOC2, GDPR, and PCI DSS require that banking cores maintain a forensic-quality audit trail. This audit log must be immutable, chronological, and verifiable. Modern systems move away from simple text logs toward Event Sourcing, where every state change is stored as a discrete, unchangeable event in an append-only log.
Hash Chaining and Cryptographic Integrity
To detect tampering by an internal or external attacker, the audit log can be structured as a hash chain. Each log entry contains a Message Authentication Code (MAC) or a hash of the current record plus the hash of the preceding record. If any historical record is modified or a record is removed, the subsequent hashes in the chain will no longer match, alerting the system to an integrity breach.
Course Details: Enterprise Banking Core Engineering
Why This Course?
The financial services industry is undergoing a massive architectural shift. Legacy COBOL-based systems are being decommissioned in favor of high-performance Java engines. However, the engineering skills required to build these "Level 0" systems are not taught in standard web development bootcamps. This course bridges the gap between general software engineering and the specialized world of high-frequency financial platforms. It provides engineers with the "mechanical sympathy" and distributed systems knowledge required to handle 100 million requests per second while ensuring 100% financial accuracy.
What You'll Build
You will design and implement a production-grade Enterprise Banking Core (EBC) from the ground up. This is not a CRUD application; it is a high-performance transactional engine. You will build:
An Ultra-Fast Transaction Router using the LMAX Disruptor to process transfers without lock contention.
A Multi-Region General Ledger that maintains strict consistency and supports multi-currency double-entry bookkeeping.
A Resilient Saga Coordinator to handle distributed transfers with automated compensation and rollback.
A Forensic Audit Engine that implements hash-chaining to ensure the ledger is tamper-proof.
A Self-Healing Observability Suite monitoring the four golden signals (Latency, Traffic, Errors, Saturation).
Who Should Take This Course?
This course is designed for professional peers across the engineering and product spectrum:
Software Engineers & Architects: To master low-level Java performance and distributed consistency protocols.
SRE & DevOps Engineers: To understand the unique performance tuning (ZGC/Shenandoah) and resilience patterns required for financial cores.
Product Managers: To understand the non-negotiable trade-offs between consistency and availability in banking systems.
Quality Assurance Engineers: To learn how to test for race conditions and data integrity in high-concurrency environments.
What Makes This Course Different?
Most "banking project" tutorials use simple SQL updates for account balances. This course rejects that approach as non-scalable. We focus on Every Day Coding Constraints, where students must implement the core logic from scratch—building the ring buffers, handling memory barriers, and implementing cryptographic chains without relying on high-level abstractions. This is an advanced-level course that prioritizes practical implementation and "hard-earned wisdom" from the fintech trenches over abstract theory.
Key Topics Covered
Java Memory Model (JMM): Understanding volatile, atomic operations, and memory barriers.
Mechanical Sympathy: CPU cache line alignment, padding, and lock-free data structures.
Numerical Engineering: Mastering BigDecimal, rounding modes, and fixed-point arithmetic.
Distributed Patterns: Sagas, Outbox patterns, and Kafka exactly-once semantics.
Persistence Architectures: Event Sourcing vs. Command Sourcing for immutable ledgers.
Performance Tuning: Optimizing ZGC and Shenandoah for sub-millisecond tail latencies.
Prerequisites
Languages: Proficiency in Java (understanding of Generics, Multithreading, and JVM basics).
Concepts: Familiarity with SQL, ACID properties, and basic networking.
Tools: Git, Docker, and an IDE (IntelliJ/Eclipse).
Mindset: A commitment to coding every day and a deep respect for the critical nature of financial data.
---
Course Structure: The 90-Day Hyperscale Roadmap
The curriculum is structured into ten major sections, moving from the foundational data model to production-ready global architectures.
---
Curriculum: List of All 90 Lessons
Section 1: The Financial Foundation (Days 1–9)
Learning Objective: Establish the canonical banking data model and ensure numerical correctness through Java precision types.
Day 1: The Banking Identity Model: Coding the Client and Identity entities with 3NF constraints.
Day 2: Anatomy of a Ledger Account: Implementing Account types (Savings, Checking, GL) and their relationships.
Day 3: The Double-Entry Primitive: Creating the JournalEntry class—the atomic unit of every transfer.
Day 4: BigDecimal vs. Binary Floating Point: Implementing the Money value object and demonstrating float errors.
Day 5: Mastering Rounding Modes: Implementing "Banker's Rounding" (HALF_EVEN) for interest calculations.
Day 6: Currency & Scaling Units: Managing multi-currency accounts and fractional precision scaling.
Day 7: The Chart of Accounts (COA): Implementing the hierarchy of internal balances and ledger heads.
Day 8: Validation Framework: Building the "Self-Defending" logic for overdrafts and balance invariants.
Day 9: Canonical Serialization: Ensuring JSON representations of financial data are consistent and lossless.
Section 2: Local Transaction Engineering (Days 10–18)
Learning Objective: Mastering Java's concurrency primitives to handle concurrent account updates safely on a single node.
Day 10: Synchronized Balance Updates: The "Naive" implementation and its performance pitfalls.
Day 11: ReentrantLock & Fair Queuing: Improving throughput and preventing thread starvation.
Day 12: Deadlock Detection & Prevention: Implementing account ID ordering to avoid circular waits.
Day 13: StampedLock & Optimistic Reads: Building a high-performance account lookup cache.
Day 14: ReadWriteLock for Analytics: Balancing transactional writes with heavy reporting queries.
Day 15: AtomicReference & CAS Updates: Transitioning toward non-blocking balance increments.
Day 16: Thread-Safe Collections: Comparing ConcurrentHashMap vs Collections.synchronizedMap for ledger storage.
Day 17: Condition Variables for Transfers: Using await and signal for cross-account synchronization.
Day 18: Testing for Race Conditions: Using CountDownLatch and CyclicBarrier to stress test the core.
Section 3: The High-Throughput Engine (Days 19–27)
Learning Objective: Implementing the LMAX Disruptor architecture for ultra-low latency transaction routing.
Day 19: Architecture of the Ring Buffer: Coding the circular array and sequence management.
Day 20: Pre-allocation & Object Reuse: Eliminating GC pressure during the hot path of transaction entry.
Day 21: Sequence Barriers & Coordination: Managing dependencies between producers and consumers.
Day 22: Cache Line Alignment (Padding): Implementing the "Long Padding" technique to avoid false sharing.
Day 23: Single Producer vs Multi-Producer: Performance trade-offs in different entry strategies.
Day 24: Implementing Wait Strategies: Coding BusySpin and Yielding strategies for low latency.
Day 25: Batching Consumers: Learning to process multiple ledger entries in a single event handler cycle.
Day 26: The Dependency Graph: Orchestrating "Audit -> Fraud Check -> Ledger Post" as sequential steps.
Day 27: Measuring Latency Jitter: Using micro-benchmarking to identify "stalls" in the ring.
Section 4: Persistence & Command Sourcing (Days 28–36)
Learning Objective: Designing a durable, append-only system of record that supports full state recovery.
Day 28: Write-Ahead Logging (WAL): Implementing the sequential log for crash recovery.
Day 29: Event Sourcing Fundamentals: Coding the EventStore and moving away from "Current State" databases.
Day 30: Command Sourcing Pattern: Capturing the "Intent" vs the "Event" in the transaction flow.
Day 31: Snapshotting for Fast Recovery: Implementing periodic balance snapshots to avoid full log replays.
Day 32: Asynchronous Log Flushes: Balancing durability (disk I/O) with performance.
Day 33: Idempotent Command IDs: Ensuring that replayed commands don't double-post transactions.
Day 34: CQRS (Command Query Responsibility Segregation): Separating the write model from the read model.
Day 35: Database Sharding Strategies: Partitioning account data by Region or Account ID.
Day 36: Schema Evolution: Handling versioning of ledger events without breaking the audit trail.
Section 5: Distributed Ledger Consistency (Days 37–45)
Learning Objective: Scaling the core across distributed nodes with exactly-once delivery guarantees.
Day 37: Kafka as a Distributed Log: Configuring Kafka for high-availability financial streams.
Day 38: The Transactional Producer: Configuring transactional.id for atomic multi-topic writes.
Day 39: Idempotent Producer Semantics: Understanding PID and sequence numbers in message streams.
Day 40: Fencing Out Zombie Producers: How Kafka handles network partitions without duplicate postings.
Day 41: Consumer Isolation Levels: Implementing read_committed to filter out aborted transactions.
Day 42: Transactional Offset Management: Committing consumer offsets as part of the producer transaction.
Day 43: Handling Transaction Timeouts: Recovery logic for stalled or hung transactions.
Day 44: Exactly-Once in a Microservices Flow: The "Consume-Transform-Produce" coding pattern.
Day 45: Broker-Level EOS Tuning: Configuring the transaction coordinator for high-scale throughput.
Section 6: The Saga of Distributed State (Days 46–54)
Learning Objective: Engineering complex, multi-service transactions with automated rollback capabilities.
Day 46: Saga State Machine Design: Implementing the SagaInstance and State transitions.
Day 47: Choreography Implementation: Implementing the event-driven Saga for a cross-bank transfer.
Day 48: Orchestration Implementation: Building the central SagaCoordinator and flow manager.
Day 49: Coding Compensating Transactions: Logic for reversing a debit if a credit fails.
Day 50: The Transactional Outbox Pattern: Atomic local state updates and event publishing.
Day 51: Handling "In-Flight" Transactions: Implementing the Reserved vs Committed balance logic.
Day 52: Timeout and Expiry Handlers: Preventing Sagass from hanging in indefinite states.
Day 53: Idempotent Event Consumers: Using unique Saga IDs to prevent duplicate processing.
Day 54: Visualizing Distributed State: Implementing distributed tracing (OpenTelemetry) for the Saga flow.
Section 7: Forensic Integrity & Auditing (Days 55–63)
Learning Objective: Building a tamper-proof auditing system that provides cryptographic proof of ledger state.
Day 55: The Anatomy of a Secure Log: Defining metadata for user, action, and classification.
Day 56: Implementing SHA-256 Hash Chains: Linking log entries to detect modification or deletion.
Day 57: Digital Signatures for Transactions: Using ECDSA to sign ledger entries at the point of origin.
Day 58: HMAC for Internal Verification: Using keyed hashes for private ledger integrity checks.
Day 59: Immutable Storage Connectors: Integrating with AWS S3 Object Lock or similar immutable stores.
Day 60: Tamper Detection Scanning: Building a periodic background scanner to verify the hash chain.
Day 61: Audit Trail Query API: Implementing secure, paginated access to the forensic log.
Day 62: Redaction and Privacy: Coding "PII Scrubbing" for audit logs to comply with GDPR.
Day 63: Verification Performance: Optimizing hash validation for production-scale log volumes.
Section 8: Resilience & Error Budgets (Days 64–72)
Learning Objective: Applying SRE principles to ensure the banking core remains operational under extreme load and failure.
Day 64: SLOs for Financial Transactions: Defining SLIs for availability, latency, and throughput.
Day 65: Circuit Breakers for Downstream APIs: Implementing Resilience4J to protect the core from slow peers.
Day 66: Adaptive Retries and Exponential Backoff: Coding smart retry logic for transient network failures.
Day 67: Bulkhead Isolation: Partitioning resources to prevent one slow customer from impacting others.
Day 68: Rate Limiting and Throttling: Implementing Token Bucket algorithms for API access.
Day 69: The Four Golden Signals: Building the Prometheus/Grafana dashboard for the core.
Day 70: Automated Incident Response: Coding runbooks for saturation and resource exhaustion.
Day 71: Blameless Post-Mortem Design: Creating the structural framework for incident analysis.
Day 72: Chaos Engineering in the Ledger: Injecting latency into the persistence layer to verify resilience.
Section 9: JVM & Infrastructure Tuning (Days 73–81)
Learning Objective: Low-level performance engineering to minimize tail latencies and maximize core efficiency.
Day 73: Garbage Collection Deep Dive: Comparing G1 vs ZGC for 100GB+ heaps.
Day 74: Tuning ZGC for Ultra-Low Latency: Configuring colored pointers and load barriers.
Day 75: Shenandoah Concurrent Compaction: Evaluating fragmentation reduction in high-churn ledgers.
Day 76: JVM Heap Sizing Strategy: Mastering -Xms and -Xmx for predictable performance.
Day 77: Thread Affinity and Core Pinning: Using JNI to lock banking threads to specific CPU cores.
Day 78: Huge Pages and TLB Optimization: Reducing memory management overhead for large ledger caches.
Day 79: JIT (Just-In-Time) Profiling: Identifying "Hot Spots" and preventing de-optimization.
Day 80: Network Stack Optimization: Implementing Kernel Bypass or Zero-Copy for high-speed API ingest.
Day 81: Monitoring GC Safepoints: Reducing "Stop-The-World" jitters in transactional paths.
Section 10: Production Hyperscale (Days 82–90)
Learning Objective: Finalizing the architecture for global deployment and 100M RPS capability.
Day 82: Multi-Region Deployment Patterns: Active-Passive vs Multi-Active Distributed Transactions.
Day 83: Data Residency and Compliance: Coding regional data pinning for GDPR/RBI regulations.
Day 84: Load Balancing and Health Checks: Configuring Route 53 and ALBs for regional failover.
Day 85: The "Thundering Herd" Simulation: Preparing for sudden spikes in transaction volume.
Day 86: Security Hardening: Final mTLS, IAM, and VPC segmentation for the production environment.
Day 87: Blue-Green Deployment for the Core: Zero-downtime updates for critical financial services.
Day 88: Stress Test - The 100M RPS Run: Final benchmark of the engine in a distributed cluster.
Day 89: Final Architectural Review: Consolidating the project documentation and scalability reports.
Day 90: Capstone Presentation & Launch: Deployment of the production-ready Enterprise Banking Core.
---
Learning Objectives by Section
S1: The Financial Foundation
Upon completion, students will be able to design a canonical banking data model that strictly adheres to 3NF standards and implements the double-entry bookkeeping principle. They will demonstrate mastery over Java's BigDecimal and precision math, ensuring that all financial calculations are free from floating-point representation errors.
S2: Local Transaction Engineering
Students will acquire the ability to manage high-concurrency account updates on a single node without race conditions or deadlocks. They will be proficient in selecting the optimal locking strategy (e.g., StampedLock vs. ReentrantLock) based on the specific contention profile of the transaction engine.
S3: The High-Throughput Engine
Upon finishing this section, students will have implemented a production-ready LMAX Disruptor ring buffer. They will understand the concept of "mechanical sympathy" and be able to apply cache-line padding and lock-free concurrency to achieve sub-millisecond tail latencies at millions of requests per second.
S4: Persistence & Command Sourcing
Students will transition from traditional "current state" persistence to an immutable, event-driven storage model. They will implement Command Sourcing and Write-Ahead Logging (WAL) to ensure that the ledger state can be completely rebuilt from a sequence of historical events with 100% fidelity.
S5: Distributed Ledger Consistency
Upon completion, students will be able to scale their transaction engine across multiple nodes using Apache Kafka. They will implement Kafka transactions and exactly-once semantics to ensure that distributed transfers are atomic and idempotent, even in the face of partial system failures.
S6: The Saga of Distributed State
Students will master the Saga pattern for managing distributed transactions across microservices. They will be capable of implementing both Orchestration and Choreography models, including the logic for automated compensating transactions to maintain eventual consistency in complex financial workflows.
S7: Forensic Integrity & Auditing
Upon finishing this section, students will have built a cryptographically secure audit trail. They will be proficient in hash-chaining and digital signatures, enabling them to provide verifiable proof of ledger integrity and meet stringent regulatory requirements for forensic investigations.
S8: Resilience & Error Budgets
Students will apply Site Reliability Engineering (SRE) best practices to the banking core. They will be able to define SLIs/SLOs, implement circuit breakers and rate limiters, and design self-healing systems that can survive high-load scenarios without impacting customer financial data.
S9: JVM & Infrastructure Tuning
Upon completion, students will be expert performance engineers of the Java platform. They will be able to tune advanced garbage collectors like ZGC and Shenandoah, configure thread affinity, and optimize the network stack to eliminate jitter and achieve predictable performance in a production environment.
S10: Production Hyperscale
In the final section, students will synthesize all previous learnings to deploy a global-scale banking core. They will understand the trade-offs of multi-region architectures and be prepared to launch a system capable of handling hyperscale volume with the reliability and security expected of a total-tier financial institution.